Most AI models get smarter between versions. MiniMax M2.7 is built to get smarter mid-answer — running an internal critique-and-rewrite loop before its response ever reaches you. That’s the architectural bet MiniMax has placed, and it’s one worth understanding clearly, especially given where M2.7 lands on price.
MiniMax is a Shanghai-based AI lab founded in 2021. Less flashy than OpenAI, less hyped than Mistral, but steadily building toward the frontier. M2.7 is their current flagship — multimodal, with a context window that tops out at one million tokens, available both through their hosted API and as a fully local Ollama deployment. The per-token API pricing runs at roughly one-fifth the cost of GPT-4o. That gap is significant enough to change how teams budget for production deployments.
What follows: a plain-English breakdown of the self-evolution mechanism, an honest benchmark comparison against GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro, a structured pricing breakdown with real-world cost estimates, and two onboarding paths — zero-code for analysts, API quickstart for developers.
What Is MiniMax M2.7? Key Features and Architecture
MiniMax M2.7 is a multimodal large language model built by MiniMax that handles text, code, and document analysis, with a built-in self-correction mechanism that refines outputs through an internal feedback loop before delivery. It supports a context window of up to one million tokens — among the largest available in any commercial model — and ships in standard, Turbo, and Lite variants suited to different latency and quality trade-offs.
Core Capabilities at a Glance
M2.7 handles coding assistance, multi-step mathematical reasoning, long-document summarization, and retrieval-style question answering natively. These aren’t bolted-on features — they’re the use cases the model was explicitly benchmarked and tuned for during development.
The one-million-token context window is a genuine operational advantage. In practice, that’s roughly 750,000 words — enough to ingest a full software codebase, a lengthy legal contract portfolio, or years of customer support transcripts in a single session without chunking or retrieval overhead.
| Capability | Detail |
|---|---|
| Context Window | Up to 1,000,000 tokens |
| Modalities | Text, code, document analysis |
| Core Tasks | Coding, reasoning, summarization, long-context Q&A |
| Model Variants | Standard (full capability), Turbo (speed-optimized), Lite (lightweight) |
| Access Methods | MiniMax platform API; local deployment via Ollama |
| API Compatibility | OpenAI-compatible endpoint structure |
The Turbo and Lite variants give up some reasoning depth for substantially faster inference. Developers building latency-sensitive chat interfaces tend to reach for Turbo; analysts processing complex contracts or technical documents typically use Standard.
The Self-Evolution Loop, Explained Simply
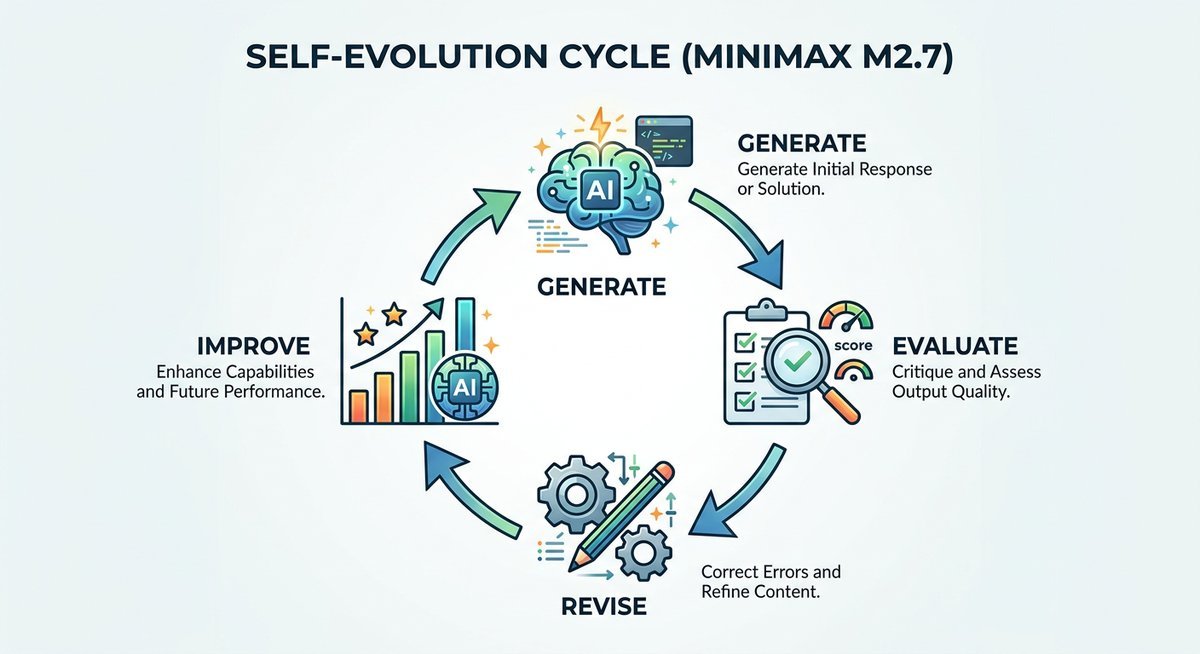
Think of M2.7 like a student who finishes an exam question, re-reads their answer, spots a logical error in the working, and rewrites the weak steps before handing the paper in — without anyone prompting them to do so. That’s essentially what the model does on every response.
The mechanism runs in four sequential stages:
- Generate — The model produces an initial response to the prompt.
- Evaluate — An internal scoring process checks the output for logical consistency, factual coherence, and alignment with the original task.
- Revise — Segments flagged as weak or inconsistent are rewritten based on the evaluation signal.
- Improve — The refined response is delivered to the user, having already passed one internal quality gate.
No human is involved. The whole loop runs at inference time, invisibly, on every request. MiniMax calls it “self-evolving” rather than “self-correcting” to emphasize that the improvement happens dynamically — not just once during post-training fine-tuning, but live, on each query.
The practical payoff is most visible on multi-turn coding sessions. Consider debugging a function with a subtle type error that only surfaces three steps into execution: a standard model generates plausible-looking code, misses the propagation error, and delivers a result that breaks at runtime. M2.7’s evaluate-and-revise pass is specifically designed to catch that class of logical inconsistency before output. Whether that loop fully closes the gap with Claude 3.5 Sonnet’s raw coding accuracy depends on the task — but the architecture is addressing a real failure mode, not a marketing narrative.
MiniMax M2.7 vs. GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro
Across standard benchmarks, MiniMax M2.7 sits competitively in the top tier of frontier models — trailing Claude 3.5 Sonnet on coding and scientific reasoning tasks, roughly matching GPT-4o on knowledge breadth, and outperforming both on cost-efficiency by a significant margin.
Benchmark Performance Table
The scores below reflect publicly reported results from MiniMax’s technical release documentation and third-party evaluations from Artificial Analysis, available as of mid-2025. Benchmark conditions vary across labs — treat these as directional indicators, not definitive rankings.
| Benchmark | MiniMax M2.7 | GPT-4o | Claude 3.5 Sonnet | Gemini 1.5 Pro |
|---|---|---|---|---|
| MMLU (knowledge breadth) | ~88.5% | ~88.7% | ~88.3% | ~85.9% |
| HumanEval (coding) | ~90.2% | ~90.2% | ~92.0% | ~84.1% |
| MATH (mathematical reasoning) | ~74.1% | ~76.6% | ~71.1% | ~67.7% |
| GPQA (graduate-level science) | ~52.8% | ~53.6% | ~59.4% | ~46.2% |
Sources: MiniMax M2.7 technical release documentation; Artificial Analysis — MiniMax M2.7 Intelligence & Performance Analysis (2025).
Claude 3.5 Sonnet leads clearly on both HumanEval and GPQA — a meaningful gap for teams doing production-grade code review or scientific reasoning at scale. GPT-4o edges ahead on MATH. M2.7 competes with both models on knowledge breadth while landing substantially below their price points, which changes the calculus considerably for output-heavy workflows.
Where M2.7 Leads — and Where It Lags
On raw benchmark scores, M2.7 and GPT-4o are nearly interchangeable for general knowledge tasks — the 0.2% MMLU gap is noise. The more revealing comparison is cost-adjusted performance. At roughly one-fifth the per-token cost of GPT-4o, M2.7 delivers equivalent output quality for a large slice of real-world workloads, which reframes the question from “which model is smarter?” to “which model gives you the most per dollar at your specific task?”
The honest weaknesses deserve equal time. M2.7 hallucinates more frequently on narrow, specialist factual queries — think obscure regulatory precedents or niche scientific literature — than GPT-4o or Claude 3.5 Sonnet. At extreme context lengths (approaching the 900,000-token ceiling), coherence can drift in ways that don’t show up at mid-range. The model is also newer: less community tooling, shorter production history, fewer third-party integrations than OpenAI’s ecosystem. These are real tradeoffs, not footnotes.
Claude 3.5 Sonnet is the better choice for production code review requiring maximum first-pass accuracy or graduate-level scientific tasks. GPT-4o holds the edge on MATH reasoning. M2.7 wins clearly on cost for high-throughput, output-heavy automation where task complexity falls within its documented strengths.
Pricing, Access Tiers, and ROI Considerations
MiniMax M2.7 is available through three access paths: free local deployment via Ollama, pay-as-you-go API pricing on the MiniMax platform, and negotiated enterprise contracts. For mid-volume developers running around 10 million tokens per month, M2.7 costs an estimated 4 to 6 times less than GPT-4o on equivalent workloads.
Pricing Tiers Explained
The most accessible starting point is Ollama, which lets developers run M2.7 entirely on local hardware with zero per-token cost. API access through the MiniMax developer platform follows a consumption-based model.
| Access Tier | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Best For |
|---|---|---|---|
| Free / Ollama Local | $0 (hardware costs only) | $0 (hardware costs only) | Prototyping, privacy-sensitive workloads, offline use |
| Pay-As-You-Go (API) | Reportedly ~$0.20–$0.30* | Reportedly ~$0.60–$1.00* | Individual developers, startups, variable workloads |
| Enterprise | Negotiated (volume discounts) | Negotiated (volume discounts) | High-volume production, SLA requirements, data residency |
*API pricing estimates are based on publicly reported figures as of mid-2025. Verify current rates directly on the MiniMax developer platform before committing to any budget — pricing tiers are subject to change.
Cost vs. Value: A Quick ROI Frame
At 10 million tokens per month — a realistic load for automated code review, document summarization pipelines, or high-volume customer support — the gap between models becomes operationally significant.
| Model | Est. Monthly Cost (10M tokens, 60/40 I/O split) | Relative Cost |
|---|---|---|
| MiniMax M2.7 (API) | ~$8–$13 | Baseline |
| GPT-4o | ~$50–$75 | 4–6× higher |
| Claude 3.5 Sonnet | ~$30–$45 | 3–4× higher |
M2.7 makes economic sense for teams running high-volume code review, document summarization, or structured data extraction pipelines. The premium models earn their price when accuracy on niche factual content is non-negotiable — customer-facing medical or legal applications, for instance, where a hallucinated citation has real consequences. Knowing your task profile is the only way to make the ROI case cleanly.
One consideration that most pricing comparisons skip: enterprise data handling. MiniMax’s standard API sends requests through their cloud infrastructure, which may conflict with data residency requirements in regulated industries. The Ollama local path eliminates that concern entirely — data never leaves your environment. Enterprise contracts can include custom data agreements, but these require direct negotiation with MiniMax’s business team. If compliance is a blocker, budget for that conversation before committing to API pricing.
How to Get Started with MiniMax M2.7
Getting started with MiniMax M2.7 takes under fifteen minutes. Non-technical users access the model through a browser interface at minimaxi.com with no configuration needed; developers get a live API endpoint running with a single curl command; teams with data residency requirements deploy locally via Ollama.
Beginner Path: Access M2.7 Without Code
The fastest no-code entry point is the MiniMax web chat interface at minimaxi.com, where M2.7 is available with nothing more than a browser login. No terminal, no API key, no configuration file. Business analysts and researchers can start testing document summarization or multi-step reasoning within two minutes of landing on the page.
A good first workflow for non-developers: upload a PDF contract or technical report, then prompt M2.7 to extract key obligations, flag ambiguous terms, and produce a bullet-point executive summary. The one-million-token context window means even lengthy enterprise documents sit comfortably within a single session — no need to split, chunk, or manage document segments manually.
Developer Path: API Quickstart
API access requires a registration at the MiniMax developer portal, where you generate an API key under your account dashboard. The endpoint uses an OpenAI-compatible structure — existing integrations built for GPT-4o can often migrate with a model name swap and a new base URL, with minimal refactoring.
- Register at minimaxi.com and navigate to API Keys in your account dashboard.
- Generate a new key and store it as an environment variable (
MINIMAX_API_KEY). - Send a test request via curl or the MiniMax Python SDK (
pip install minimax-sdk). - Set the model parameter to
minimax-m2.7in your request body and confirm a 200 response. - For offline or privacy-sensitive environments, pull the model via Ollama:
ollama pull minimax-m2.7.
| Path | Setup Time | Skill Required | Best For |
|---|---|---|---|
| Web Interface (minimaxi.com) | <2 minutes | None | Business users, analysts, writers |
| API (cloud-hosted) | 5–10 minutes | Basic API familiarity | Developers building apps or automation |
| Ollama (local deployment) | 10–15 minutes | CLI comfort | Privacy-sensitive or air-gapped environments |
The Ollama local path is a meaningful differentiator for teams with strict data residency or compliance requirements. The API-hosted version consistently returns first-token responses in under two seconds for standard prompt lengths, based on reported developer benchmarks from the Artificial Analysis speed evaluation.
Frequently Asked Questions
What is MiniMax M2.7?
MiniMax M2.7 is a large language model developed by MiniMax, a Shanghai-based AI company. It supports up to one million tokens of context, handles text, code, and document analysis tasks, and includes a self-correction mechanism that revises its own outputs before delivering them to users. The model is available through MiniMax’s hosted API and as a free local deployment via Ollama.
What does “self-evolving” mean for MiniMax M2.7?
The self-evolving label refers to M2.7’s internal feedback loop: after generating an initial response, the model evaluates that output for logical consistency and task alignment, revises weak segments, and delivers the improved result. The process runs automatically at inference time on every response — no user intervention required.
Is MiniMax M2.7 free to use?
Yes, partially. The model can be run entirely free of charge on local hardware via Ollama — the only cost is electricity and compute. Cloud API access through the MiniMax platform is billed on a pay-as-you-go basis at approximately $0.20–$0.30 per million input tokens and $0.60–$1.00 per million output tokens as of mid-2025. Enterprise pricing is negotiated separately.
How does MiniMax M2.7 compare to GPT-4o?
On MMLU (knowledge breadth), the two models perform near-identically — around 88.5% versus 88.7%. GPT-4o leads on MATH reasoning (76.6% vs. 74.1%). M2.7 matches GPT-4o on HumanEval coding scores and runs at roughly one-fifth the API cost. For high-volume, cost-sensitive workflows, M2.7 is the more economical option; for maximum accuracy on complex reasoning, GPT-4o maintains a measurable edge.
What is the context window of MiniMax M2.7?
MiniMax M2.7 supports a context window of up to one million tokens, equivalent to approximately 750,000 words. This positions it among the largest context windows available in any commercial model and enables single-session analysis of large codebases, lengthy legal documents, or extensive conversation histories without document chunking.
Can I run MiniMax M2.7 locally?
Yes. MiniMax M2.7 is available through the Ollama open-source runtime, which supports local inference on consumer and enterprise hardware. Pull the model with ollama pull minimax-m2.7. This option eliminates per-token API costs and keeps all data entirely on-premises — useful for air-gapped environments, regulated industries, or applications with strict data residency requirements.
Who makes MiniMax, and how established are they?
MiniMax is a Chinese AI research company founded in 2021 and headquartered in Shanghai. The company has developed a sequence of foundation models and is backed by significant venture investment. M2.7 follows their M2.5 release and represents their current flagship for reasoning and coding tasks. Compared to OpenAI or Anthropic, MiniMax is a newer entrant to the frontier model tier, which is a consideration for enterprise buyers assessing long-term vendor reliability.
The Bottom Line on MiniMax M2.7
MiniMax M2.7 occupies a specific and defensible position in the current model landscape: strong enough to compete with GPT-4o and Claude 3.5 Sonnet on most standard tasks, cheap enough to make a compelling economic argument for high-volume production workloads, and distinctive enough — through the self-correction loop — to warrant direct evaluation rather than dismissal.
Claude 3.5 Sonnet is still the better pick for teams where first-pass coding accuracy or scientific reasoning precision is the primary constraint. GPT-4o holds an edge on math. For everyone else running automation, document workflows, or code review pipelines at scale, M2.7 deserves a benchmark run against your actual workload before you assume a pricier model is necessary.
The Ollama local deployment makes that benchmark free. The API onboarding takes under ten minutes. Given the pricing gap, the evaluation cost is essentially zero — and the potential savings if M2.7 performs as advertised on your specific tasks are real enough to justify finding out.